
How parallelizing your builds can slow them down
Or at least, make it seem that way! This post explores what happens to your CI pipelines when all your workers are busy.


Most CI systems allow you to spread work across multiple machines. This means that you can spread out builds and deploys to run in parallel, so your releases can complete more quickly. When resources are plentiful, releases speed up, everyone’s happy. But paradoxically, when things get busier, it can make your releases take longer!
Who is this post for?
Your first thought might be that the slowdown is because of cold starts. Tasks like starting containers, setting up tools and cloning from Git. As an LLM might say, you’re absolutely right! These up-front tasks absolutely have an impact on each job, and the more jobs you have, the bigger the impact.
But today we’re looking at something a little different. We’ll be looking at time spent queueing, and in particular what happens during busy times when your queue is growing.
This will be most relevant when you’re managing a fixed or manually scaled set of workers. This could come into play with platforms like Jenkins (without k8s), TeamCity and self-hosted GitHub Actions.
It’s less relevant when you have a fully autoscaled pool, or work is done in ephemeral containers. If you’re working with platforms like Jenkins (with k8s), Argo Workflows, or Tekton, scaling is more a function of cluster size rather than available workers.
So if you’re frustrated by frequently delayed builds, or figuring out how to scale your worker pool effectively, read on. If not, you’re welcome to stay and hang out. I brought diagrams!
Working an example
Let’s look at an example release pipeline based on the kinds of pipelines I saw in a previous job. It builds an application, deploys it to two staging environments, runs acceptance tests and then promotes to 4 production environments. The deployments can all be parallelized.
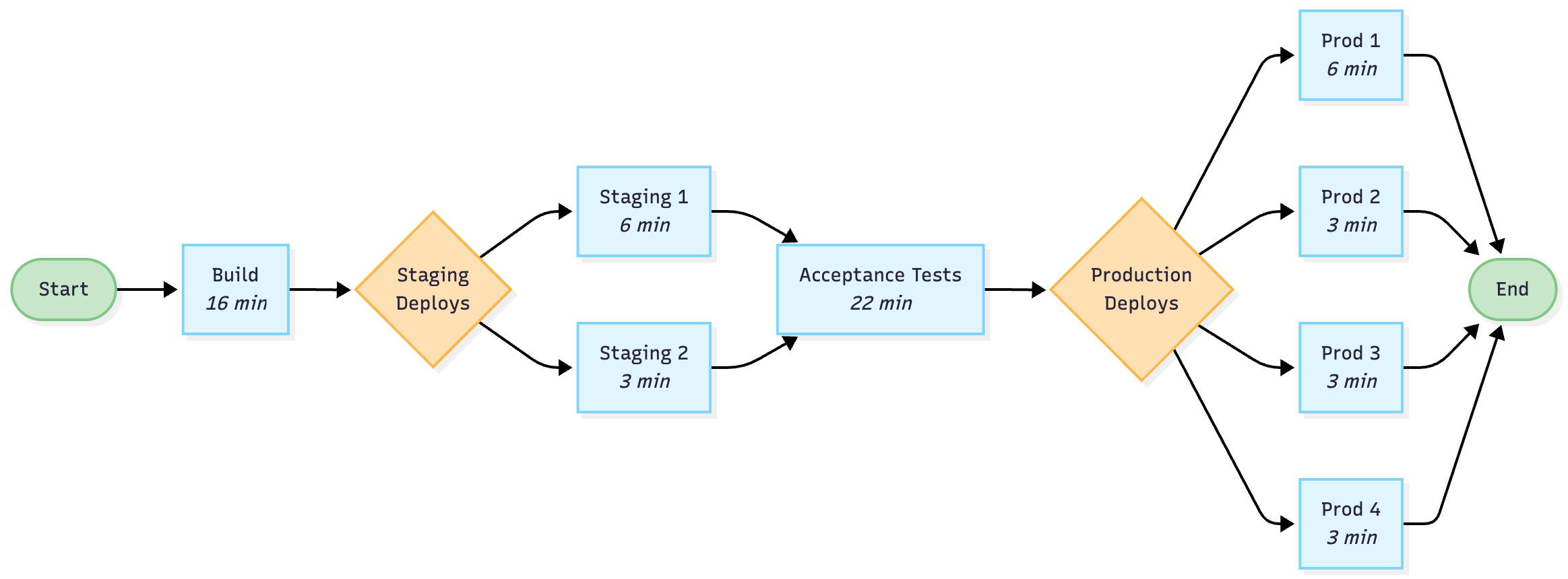
I’ve included some example timings, with a total of 62 minutes of work. If we have 4 workers available, we can run our deploys concurrently, which saves about 12 minutes per release. Very nearly 20%!

So parallelization seems like a no-brainer, right? Well this is just an ideal scenario, and there is a lot of idle time for 3 of the workers. What if our workers were always busy?
With only 3 workers, but 5 releases, jobs start having to wait in a queue until a worker is available. So the actual execution gets more spread out.

The second release, highlighted in red is spread out over a much longer period, because each subsequent job has to wait for one of the workers to be available. Our 50 minute release has now become an hour and a half! And let’s face it, 50 minutes wasn’t amazing to begin with.
If we give up on parallelization, and run everything in series as a single job, we get a bit closer to our original duration. The later releases (R3 and R4) have to wait a little bit longer, but 3/5 of our releases are finishing faster. The average developer experience is better without parallelization.

Bigger numbers
Expanding these examples out a bit, I wrote a program to simulate larger numbers of releases.
Here’s sample output for a scenario with 4 workers and 100 releases, with a new release being started every 15 minutes:
=== Serial jobs ===
Releases: 100
Mean: 86
Median: 86
Standard Deviation: 14.422205101855956
Minimum: 62
Maximum: 110
=== Parallel jobs ===
Releases: 100
Mean: 94.8
Median: 95
Standard Deviation: 21.894291493446417
Minimum: 50
Maximum: 136Two things to note here, when parallelizing our deploys, the fastest releases are indeed faster, but on average, a release takes 10% longer than with serial jobs. This gets worse as the queues get longer. If we bump the arrival time to every 5 minutes, the average parallel releases take almost twice as long as serial ones! Not only that, but even the fastest release is slower.
=== Serial jobs ===
Releases: 100
Mean: 566
Median: 566
Standard Deviation: 302.8663071389751
Minimum: 62
Maximum: 1070
=== Parallel jobs ===
Releases: 100
Mean: 885.05
Median: 1030
Standard Deviation: 288.53767085079215
Minimum: 85
Maximum: 1112If you want to play around with some numbers yourself, I published the code here. Fair warning, it’s not my cleanest work!
Why does this matter?
If your team manages your own CI/CD workers, you may be tempted to save some money by reducing workers so they’re all as busy as possible. Really get your money’s worth by minimizing idle compute time. But hopefully these examples show that this can have serious impact on your overall developer experience. If you’re looking to right-size your worker pool, consider how quickly releases are being queued up at peak. If you’re mathematically inclined, maybe even apply some queueing theory! If not (like me), throw together a little simulation program.
When designing a pipeline, pay close attention to how you’re separating steps up into jobs. Be aware of the cost of starting a new job. Even if you’re running on a cloud service like GitHub Actions, there will be some queueing time involved. You may be surprised how much you can improve speed by consolidating a job or two.
Up next
There’s a lot more I could cover here, so this will probably be the first post in a short series. I’m thinking future editions could graph out performance as we change our arrival time, and look at ways you could optimize your worker pool count. I might also look at cold-start time in more detail. Be sure to subscribe to follow along, and I’ll update this post with links to the rest of the series as they appear.